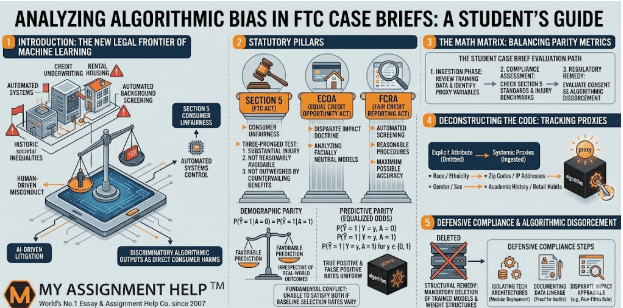
1. Introduction: The New Legal Frontier of Machine Learning
For upper-level law students navigating contemporary consumer protection coursework, the curriculum is experiencing a significant shift. Traditional administrative law and tort frameworks are no longer restricted to human-driven corporate misconduct. Instead, the modern legal landscape is increasingly dominated by automated systems. Machine learning models, predictive scoring scripts, and automated background profiling platforms now control critical consumer opportunities—ranging from credit underwriting and rental housing selection to automated workplace screening. Because these networks frequently automate and compound historic societal inequalities, they have become a primary target for federal regulatory intervention.
The Federal Trade Commission (FTC) has adapted its enforcement approach to address this automated landscape. Relying on Section 5 of the FTC Act, which prohibits unfair or deceptive trade practices, the Commission treats discriminatory algorithmic outputs as direct consumer harms. For law students tasked with drafting comprehensive case briefs or analyzing administrative enforcement actions, this shift presents a distinct academic challenge. Analyzing a modern FTC consent decree requires evaluating both legal precedents and the technical structures of the underlying software.
Navigating these overlapping statutory frameworks requires rigorous academic research; comprehensive resources can assist students in mapping out these complex FTC precedents. Utilizing authoritative law assignment help provides an objective structural roadmap for dissecting complex administrative filings, ensuring your academic analyses remain grounded in current US regulatory standards. To build a strong analysis, students must first understand the specific statutory mechanisms the Commission uses to regulate automated tools.
2. Statutory Pillars: Section 5, ECOA, and FCRA in Student Briefs
When analyzing a regulatory complaint involving artificial intelligence, your case brief must identify the specific statutory levers activated by the regulatory agency. The Commission’s primary enforcement mechanism is Section 5 of the FTC Act (15 U.S.C. § 45), which evaluates automated bias through the legal standard of consumer unfairness. To establish liability, an enforcement action must satisfy a three-pronged test: the automated practice must cause substantial consumer injury, it must not be reasonably avoidable by the consumers themselves, and it must not be outweighed by countervailing benefits to consumers or open market competition.
+———————————————————————–+
| THE STUDENT CASE BRIEF EVALUATION PATH |
| 1. INGESTION PHASE: Review training data pools and identify any |
| hidden demographic or geographic proxy variables. |
+———————————————————————–+
|
v
+———————————————————————–+
| 2. COMPLIANCE ASSESSMENT: Check the model’s performance against |
| Section 5 Unfairness standards and consumer injury benchmarks. |
+———————————————————————–+
|
v
+———————————————————————–+
| 3. REGULATORY REMEDY: Evaluate FTC interventions, including fines, |
| consent decrees, or mandatory algorithmic disgorgement orders. |
+———————————————————————–+
Beyond consumer unfairness, student research papers must distinguish between general consumer protection and specialized civil rights statutes. In financial technology cases, the FTC works alongside the Consumer Financial Protection Bureau (CFPB) to enforce the Equal Credit Opportunity Act (ECOA). Here, students must focus on the disparate impact doctrine, analyzing how facially neutral models create discriminatory barriers in lending without requiring proof of discriminatory intent. Similarly, when reviewing cases involving automated tenant screening or employment background checks, your brief must address the Fair Credit Reporting Act (FCRA), tracking whether the automated system used reasonable procedures to ensure maximum possible accuracy.
See also: The Benefits of Using Decentralized Wallets
3. The Math Matrix: Balancing Parity Metrics in Legal Analysis
A strong legal analysis of technology regulations requires evaluating the underlying statistical frameworks. When arguing or briefing an algorithmic bias case, students often encounter a fundamental mathematical conflict: a predictive system generally cannot satisfy multiple definitions of fairness simultaneously if the baseline selection rates vary across demographic groups. This friction typically manifests as a trade-off between demographic parity and predictive parity.
Let Y represent the true binary consumer outcome (such as successful loan repayment), let \hat{Y} represent the model’s binary prediction, and let A represent a protected demographic variable (such as race or gender).
Demographic Parity requires that the likelihood of receiving a favorable model prediction is equal across all demographic groups, irrespective of the underlying real-world distribution of outcomes:
P(\hat{Y} = 1 | A = 0) = P(\hat{Y} = 1 | A = 1)
Conversely, Predictive Parity (Equalized Odds) requires that the model’s accuracy metrics—specifically the true positive rates and false positive rates—are uniform across all demographic groups. This means the system must maintain equal accuracy for every protected class:
P(\hat{Y} = 1 | Y = y, A = 0) = P(\hat{Y} = 1 | Y = y, A = 1) \quad \text{for } y \in \{0, 1\}
When an engineering team develops an underwriting model, optimizing for predictive parity can inadvertently conflict with demographic parity if historical data reflects systemic inequalities. When writing a legal brief, your task is to evaluate how the deployment of these optimization metrics impacts consumer protection standards. If a corporate entity prioritizes predictive parity in a way that perpetuates historic disparities, the FTC may classify that practice as an unavoidable consumer injury under Section 5.
| Precedent Case / Source | Central Tech Challenge | Key Law School Briefing Focus |
| FTC Act Section 5 | Unfair or deceptive automated trade practices. | Quantifying substantial, unavoidable economic consumer injury. |
| Equal Credit Opportunity Act | Disparate impact in algorithmic scoring models. | Evidentiary requirements for establishing structural bias without explicit intent. |
| Fair Credit Reporting Act | Inaccurate data integration in screening platforms. | Analyzing procedural compliance and consumer dispute paths. |
| FTC v. Rite Aid Corp. (2023) | Biometric facial recognition surveillance errors. | Evaluating the scope of 5-year biometric deployment prohibitions. |
| FTC v. Kurbo / WW (2022) | Illegitimate data capture used for model training. | Analyzing the legal mechanics of mandatory algorithmic disgorgement. |
4. Deconstructing the Code: Tracking Proxies and Data Lineage
To understand how bias enters a predictive model, law students must look closely at the software engineering process. Algorithmic bias rarely stems from an intentional effort to discriminate. Instead, it typically develops during data collection, model training, and feature engineering. When building case briefs on recent enforcement actions, students must learn to identify the subtle ways data variables can serve as proxies for protected characteristics.
While developers routinely omit explicit variables like race or sex to comply with non-discrimination laws, advanced neural networks are highly effective at identifying alternative data points that correlate with those attributes. For instance, geographic identifiers (such as zip codes), historical educational institutions, and specific retail habits often mirror underlying demographic patterns. If a model excludes a protected trait but includes these highly correlated proxies, the resulting predictions will often replicate the same discriminatory biases found in the historical data.
+————————————————————————–+
| PROXY VARIABLE CORRELATION CHART |
+————————————————————————–+
| EXPLICIT ATTRIBUTE (Omitted) –> SYSTEMIC PROXIES (Ingested) |
| * Race / Ethnicity –> * Zip Codes / IP Addresses |
| * Gender / Sex –> * Academic History / Retail Habits |
+————————————————————————–+
Resolving these systemic script errors requires writing robust, auditable data architectures and implementing rigorous validation tests. When technical programming assignments intersect with these complex regulatory principles, having clear examples of clean code can be highly beneficial. Students looking to evaluate these software structures often choose to pay someone to do my programming homework to secure professionally documented script templates. Examining clean, well-commented code repositories helps future technology lawyers understand how to structure algorithmic audits and spot hidden proxy dependencies in production-ready software.
5. Defensive Compliance and the Remedy of Algorithmic Disgorgement
When analyzing the business impact of regulatory actions, student research must account for the changing nature of enforcement remedies. The FTC has shifted away from using modest financial penalties as the sole deterrent for tech companies. Instead, the Commission increasingly employs a more severe structural remedy: algorithmic disgorgement.
Under an algorithmic disgorgement order, a company is required to completely delete the trained models, weight structures, and algorithmic architectures developed using improperly acquired or biased data. For a technology enterprise, this penalty can be devastating, effectively wiping out millions of dollars in research and development and requiring engineering teams to rebuild their systems from the ground up.
When briefing cases like FTC v. Kurbo or FTC v. Rite Aid, students should look for the defensive compliance steps companies are taking to mitigate these structural risks:
- Isolating Tech Architectures: Developing modular model deployments so that an affected system can be removed and retrained without taking down the entire enterprise infrastructure.
- Documenting Data Lineage: Maintaining verifiable records of data sourcing, transformation rules, and training inputs to prove compliance during regulatory audits.
- Continuous Disparate Impact Appraisals: Implementing automated checking procedures—such as evaluating models against the four-fifths rule—to catch and address bias before deployment.
6. Conclusion: Developing Skills for the Future of Technology Law
Analyzing algorithmic bias requires a strong understanding of both administrative law and data science principles. As the FTC continues to scrutinize automated systems across the US economy, the ability to read and evaluate a machine learning case brief is becoming a valuable skill for modern legal professionals. For law and technology students, mastering this intersection is essential for building a successful career in digital compliance, privacy advocacy, or corporate advisory services.
Frequently Asked Questions (FAQ)
1. How does the FTC establish jurisdiction over automated algorithms?
The FTC establishes jurisdiction through Section 5 of the FTC Act, which grants the agency broad authority to regulate unfair or deceptive acts or practices affecting commerce. If an automated tool generates discriminatory outcomes that inflict substantial, unavoidable harm on consumers, the FTC classifies it as an unfair practice.
2. What is the difference between disparate treatment and disparate impact in algorithmic bias cases?
Disparate treatment involves intentional discrimination, such as explicitly programming a model to reject applicants based on a protected characteristic. Disparate impact occurs when a facially neutral model—using variables like zip codes or historical academic data—produces disproportionately adverse outcomes for protected groups, even if the developers had no discriminatory intent.
3. Why is algorithmic disgorgement considered a significant enforcement remedy?
Algorithmic disgorgement requires companies to completely destroy their trained models and algorithmic architectures if they were developed using biased processes or improperly collected data. This remedy goes beyond financial fines by eliminating the core technology and intellectual property of the business, forcing them to rebuild products from scratch.
4. How do proxy variables bypass explicit data restrictions in machine learning code?
Proxy variables are unsecured data inputs that correlate with protected characteristics. For example, while a model may exclude race or gender variables, it can still identify patterns in zip codes, historical education data, or consumer purchasing habits that serve as statistical stand-ins for those protected traits, leading to biased predictions.
About the Author
Marcus Vance, JD is a Senior Content Strategist and Legal Analytics Consultant at MyAssignmentHelp. He holds a Juris Doctor from Georgetown University Law Center, specializing in administrative law and emerging technology policy. With over a decade of experience bridging the gap between computer science ethics and consumer protection statutes, Marcus delivers deep-dive regulatory analysis and research support for advanced students and compliance professionals navigating corporate risk in the United States.
References and Citations
- Federal Trade Commission. (2021). Aiming for truth, fairness, and equity in your company’s use of AI. FTC Business Guidance Reports.
- Federal Trade Commission v. Rite Aid Corporation, No. 1:23-cv-10984 (S.D.N.Y. 2023).
- Barocas, S., & Selbst, A. D. (2016). Big Data’s Disparate Impact. California Law Review, 104(3), 671-732.
- Federal Trade Commission v. WW International, Inc. and Kurbo Mobile, Inc., No. 2:22-cv-01213 (C.D. Cal. 2022).
- Equal Credit Opportunity Act (ECOA), 15 U.S.C. § 1691 et seq.
- Fair Credit Reporting Act (FCRA), 15 U.S.C. § 1681 et seq.